BEAST
👉Вернуться к списку инструкций
На суперкомпьютере установлены версии 1.10.4 и 2.6, а также библиотека beagle для ускорения вычислений в BEAST.
Пользователи: Международная лаборатория статистической и вычислительной геномики
BEAST v1
Для подготовки исходных файлов используйте графический интерфейс BEAUti на своём персональном компьютере, либо воспользуйтесь пробросом GUI с головного сервера суперкомпьютера.
Для использования BEAST v1 на суперкомпьютере выполните команду подключения модуля module load BEAST/v1.10.4
Запустите графический интерфейс BEAUti, выполнив команду beauti и подготовьте xml-файл для расчёта.
Например, скопируйте файл /opt/software/beast/v1.10.4/examples/Data/apes.nes и импортируйте его в программу (File -> Import Data...).
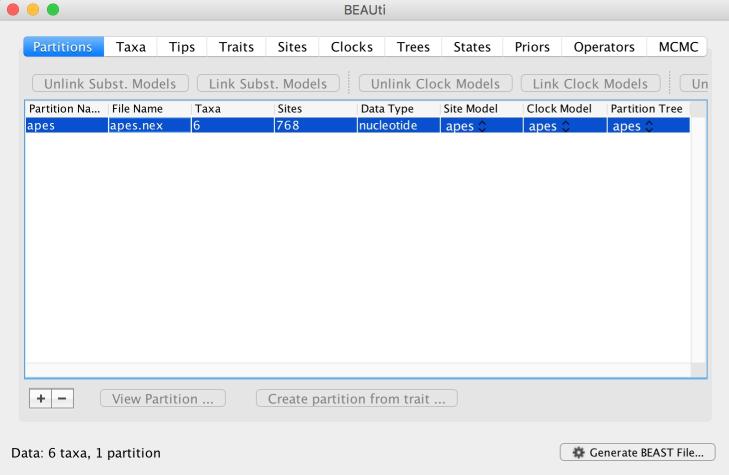
Внесите необходимые изменения и сохраните xml-файл для расчёта, нажав на кнопку Generate BEAST File... Сохраните файл apes.xml в текущую директорию.
Подготовьте скрипт-файл для очереди задач (см. инструкцию по запуску задач на суперкомпьютере).
В данном примере, расчёт будет производиться на GPU-ускорителе без деления на инстансы. В скрипт-файле необходимо подключить модуль BEAST и запросить требуемые ресурсы.
Содержимое файла beast1.sbatch:
#!/bin/bash #SBATCH --job-name=beast1 # Название задачи #SBATCH --error=beast1-%j.err # Файл для вывода ошибок #SBATCH --output=beast1-%j.log # Файл для вывода результатов #SBATCH --time=1:00:00 # Максимальное время выполнения #SBATCH -G 1 # Требуемое кол-во GPU #SBATCH -c 1 # Требуемое кол-во CPU
#SBATCH --mail-user=ваша_почта # Укажите ваш email для отправки уведомлений (если нужно)
#SBATCH --mail-type=END,FAIL # События, требующие уведомления module load BEAST/v1.10.4 # Загрузка модуля BEAST beast -beagle_cuda apes.xml # Выполнение расчёта на GPU
Для постановки задачи в очередь выполните команду sbatch beast1.sbatch
Посмотреть состояние своих задач можно с помощью команды mj
После окончания расчёта в текущем каталоге появится файл beast1-00000.log (где 00000 - номер задачи в очереди) с сообщениями, выводимыми в процессе работы BEAST. Сообщения об ошибках будут записаны в файл beast1-00000.err. Результат выполнения расчёта будет сохранён в файл <название_исходного_файла>.log (в данном случае - apes.log).
Для анализа результатов установите на персональном компьютере Tracer и FigTree (см. руководство на официальном сайте и https://bioinformatics-tutorials.readthedocs.io/en/latest/beastintro/).
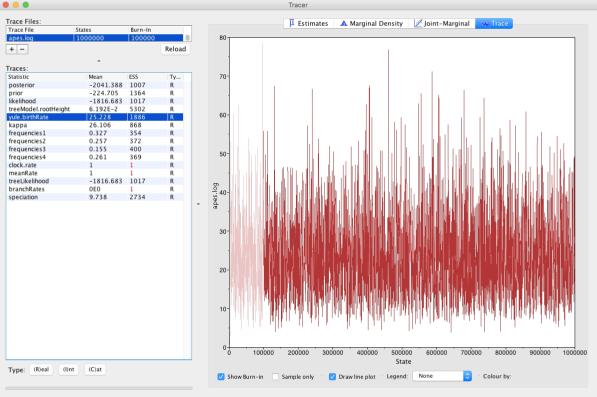
Подробные руководства по применению BEAST v1 для решения различных задач доступны на официальном сайте.
Примеры исходных данных расположены в каталоге /opt/software/beast/v1.10.4/examples
Оптимизация производительности BEAST v1
Для повышения скорости вычислений расчёт может быть разделён на несколько частей и выполнен на нескольких GPU/CPU. По умолчанию, используется максимально доступное количество потоков на CPU.
Следующие параметры влияют на процесс выполнения расчёта:
-beagle_cuda - использование GPU и параллелизации CUDA -beagle_sse - использование процессорных расширений SSE -beagle_order - определение порядка использования CPU и GPU (например, -beagle_order 2,1,0 - использовать сначала GPU #2, затем GPU #1, затем CPU) -threads - указание количества потоков при расчёте -beagle_instances - разделение расчёта на несколько инстансов, выполняющихся параллельно
Обратите внимание, что не для всех задач использование GPU-ускорителя в BEAST даст прирост производительности (а в некоторых случаях будет даже замедление).
Подробная информация о порядке применения параметров производительности и примеры использования - см. http://beast.community/performance
BEAST v2
Общий принцип работы с BEAST v2 аналогичен первой версии.
Для подготовки исходных файлов используйте графический интерфейс BEAUti на своём персональком компьютере, либо воспользуйтесь пробросом GUI с головного сервера суперкомпьютера.
Для использования BEAST v2 на суперкомпьютере выполните команду подключения модуля module load BEAST/v2.6.7 или module load BEAST/v2.7.7
Запустите графический интерфейс BEAUti, выполнив команду beauti и подготовьте xml-файл для расчёта. Примеры исходных данных расположены в каталоге /opt/software/beast/v2.6.3/examples/.
BEAST v2 поддерживает возможность установки дополнительных плагинов (пакетов) для расширения функциональности приложения. Установка пакетов производится либо через графический интерфейс BEAUti (пункт меню File -> Manage Packages), либо с использованием консольной команды packagemanager (использование: packagemanager [-list] [-add <NAME>] [-del <NAME>] [-dir <DIR>] [-help]).
Подготовьте скрипт-файл для очереди задач (см. инструкцию по запуску задач на суперкомпьютере).
В данном примере, расчёт будет производиться на CPU с 8 потоками без деления на инстансы. В скрипт-файле необходимо подключить модуль BEAST и запросить требуемые ресурсы.
Содержимое файла beast2.sbatch:
#!/bin/bash #SBATCH --job-name=beast2 # Название задачи #SBATCH --error=beast2-%j.err # Файл для вывода ошибок #SBATCH --output=beast2-%j.log # Файл для вывода результатов #SBATCH --time=1:00:00 # Максимальное время выполнения #SBATCH -c 8 # Требуемое кол-во CPU
#SBATCH --mail-user=ваша_почта # Укажите ваш email для отправки уведомлений (если нужно)
#SBATCH --mail-type=END,FAIL # События, требующие уведомления module load BEAST/v2.6.3 # Загрузка модуля BEAST beast -threads 8 H5N1.xml # Выполнение расчёта на CPU
Для постановки задачи в очередь выполните команду sbatch beast2.sbatch
Посмотреть состояние своих задач можно с помощью команды mj
После окончания расчёта в текущем каталоге появится файл beast1-00000.log (где 00000 - номер задачи в очереди) с сообщениями, выводимыми в процессе работы BEAST. Сообщения об ошибках будут записаны в файл beast1-00000.err. Результат выполнения расчёта будет сохранён в файл <название_исходного_файла>.xxx.log. Для анализа результатов установите на персональном компьютере Tracer и FigTree.
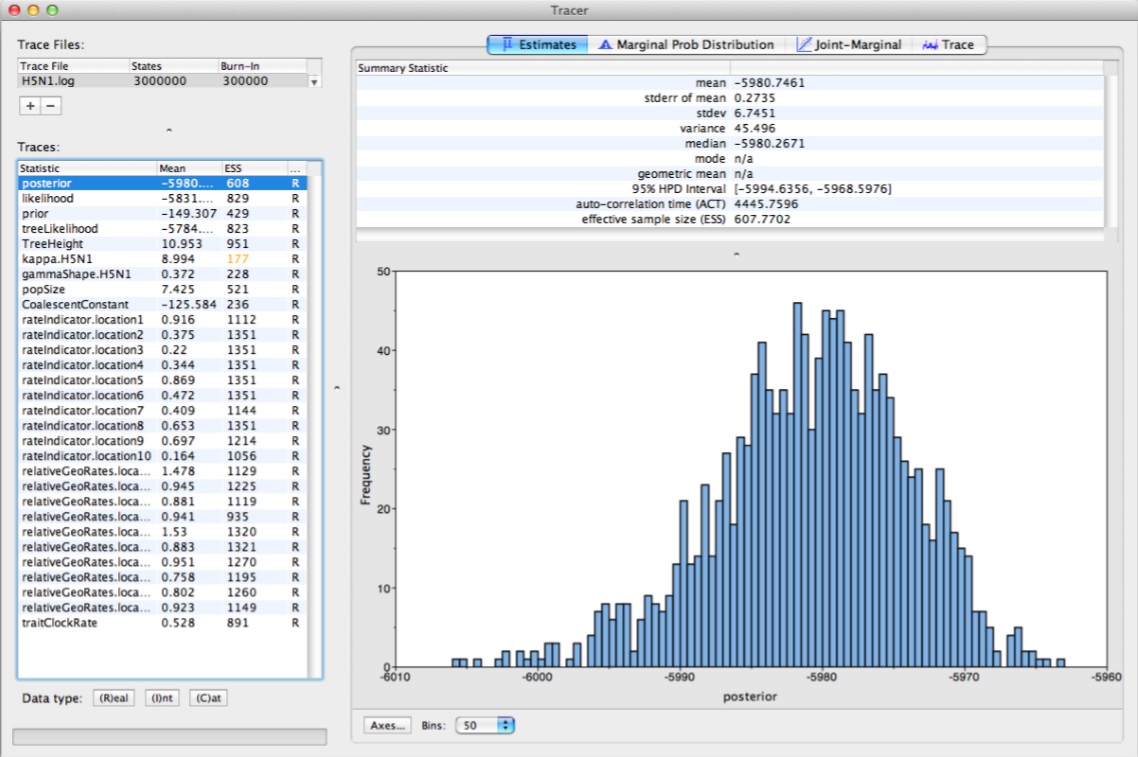
Подробные руководства по применению BEAST v2 для решения различных задач доступны на официальном сайте.
Примеры исходных данных расположены в каталоге /opt/software/beast/v2.6.3/examples
Оптимизация производительности BEAST v2
Для повышения скорости вычислений расчёт может быть разделён на несколько частей и выполнен на нескольких GPU/CPU. По умолчанию, используется максимально доступное количество потоков на CPU.
Следующие параметры влияют на процесс выполнения расчёта:
-beagle_GPU - использование GPU-ускорителя -beagle_sse - использование процессорных расширений SSE -beagle_order - определение порядка использования CPU и GPU (например, -beagle_order 2,1,0 - использовать сначала GPU #2, затем GPU #1, затем CPU) -threads - указание количества потоков при расчёте -beagle_instances - разделение расчёта на несколько инстансов, выполняющихся параллельно
Обратите внимание, что не для всех задач использование GPU-ускорителя в BEAST даст прирост производительности (а в некоторых случаях будет даже замедление).
Подробная информация о порядке применения параметров производительности и примеры использования - см. https://www.beast2.org/performance-suggestions/ и http://beast.community/performance
Полезные ссылки
- Инструкция по работе с системой HPC TaskMaster
![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.