Использование Anaconda и создание собственных Python окружений
👉 Регистрация на суперкомпьютере
👉 Инструкции для пользователей
👉 Базовая инструкция для пользователей
Обратите внимание: на вычислительных узлах и в Jupyter-ноутбуках нет доступа в Интернет. Все необходимые пакеты необходимо предварительно установить, подключившись к логин-серверу суперкомпьютера.
 Для выполнения расчетов с помощью Python, как правило, требуются дополнительные библиотеки. Оптимальным способом загрузки дополнительных библиотек на вычислительном кластере НИУ ВШЭ является использование программного пакета Anaconda. Это удобный менеджер пакетов Python, предназначенный для создания изолированных окружений Python и автоматического разрешения зависимостей. На суперкомпьютере уже имеется базовое окружение Miniconda. Для загрузки базового набора Miniconda воспользуйтесь следующей командой:
Для выполнения расчетов с помощью Python, как правило, требуются дополнительные библиотеки. Оптимальным способом загрузки дополнительных библиотек на вычислительном кластере НИУ ВШЭ является использование программного пакета Anaconda. Это удобный менеджер пакетов Python, предназначенный для создания изолированных окружений Python и автоматического разрешения зависимостей. На суперкомпьютере уже имеется базовое окружение Miniconda. Для загрузки базового набора Miniconda воспользуйтесь следующей командой:
module load python
В этом случае будет активирован модуль Miniconda с минимальной средой conda для созданий персональных окружений.
Установка других пакетов или обновление версий в базовом окружении Miniconda невозможна. Обновление версии Miniconda происходит несколько раз в год.
Также доступны дополнительные окружения с пакетами PyTorch, TensorFlow и аналогом Google Colab: module available python
Если вам необходимо установить пакеты или версии пакетов, которых нет в базовом окружении, то потребуется создать своё собственное изолированное окружение и установить в него необходимые модули:
conda create -n <имя окружения> python=<версия python>
Например, для создания окружения "my_py_env1" на базе последней версии Python 3 воспользуйтесь следующей командой:
conda create -n my_py_env1 python=3.*
На запрос об установке новых пакетов ответьте "y".Далее необходимо задействовать созданное окружение:
source activate my_py_env1
После активации в приглашении терминала появится префикс с именем окружения:
(my_py_env1) [miniconda@sms ~]$ python -V
Для вывода списка доступных окружений используйте команду conda env list
Для установки необходимых пакетов используйте команду conda install, например, для установки последней версии NumPy:
conda install numpy
Для установки пакетов из файла requirements.txt можно использовать команду conda install --file requirements.txt
Обратите внимание: на вычислительных узлах из соображений безопасности нет доступа в Интернет. Все пакеты необходимо предварительно установить, подключившись к логин-серверу суперкомпьютера.
С помощью команды conda search выполняется поиск пакетов в репозиториях Anaconda. Также поиск можно осуществлять на сайте https://anaconda.org/anaconda/
Отключить окружение (например, для выбора другого): conda deactivate
Для подключения окружения к ноутбукам в JupyterHub установите соответствующее ядро (см. https://github.com/jupyter/jupyter/wiki/Jupyter-kernels).
Например, для Python необходимо установить ядро ipykernel:
conda install ipykernel
После установки ядра это окружение появится в списке на главной странице JupyterLab:
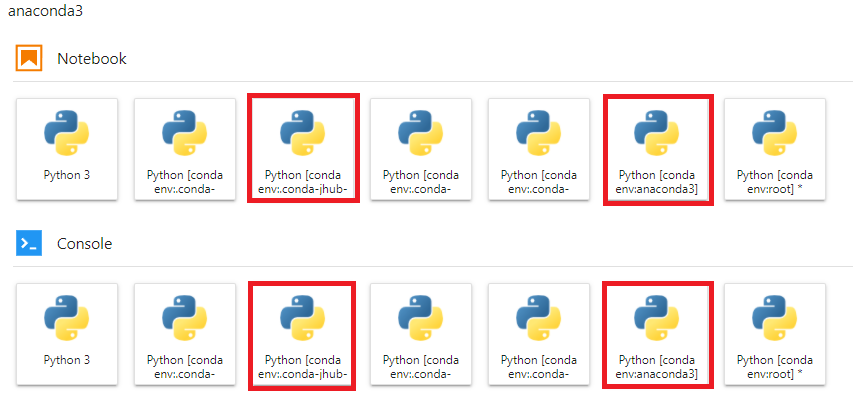 Переключить используемое окружение и ядро можно в уже запущенном ноутбуке, кликнув по названию ядра в правом верхнем углу или в меню Kernel -> Change Kernel...:
Переключить используемое окружение и ядро можно в уже запущенном ноутбуке, кликнув по названию ядра в правом верхнем углу или в меню Kernel -> Change Kernel...:
Полная документация по использованию conda: https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html
Настройка окружения Python для работы с GPU на вычислительных узлах
Для работы с GPU на вычислительных узлах необходимо предварительно настроить изолированное окружение Python на логин-сервере (sms) вычислительного кластера НИУ ВШЭ:
- Выгрузить все загруженные модули и активировать модуль Python:
module purge; module load python - Создать и активировать новое изолированное окружение Python:
conda create -n my_py_env
source activate my_py_env
Если вы часто запускаете задачи с использованием srun, то рекомендуется в файл ~/.bashrc добавить строчку source activate my_py_env. В этом случае будет автоматически активироваться созданное окружение. - Установить необходимые пакеты Python, например для PyTorch:
pip3 install torch torchvision
Большие фреймворки, такие как PyTorch или TensorFlow, рекомендуется устанавливать в первую очередь и в новое пустое окружение. Это позволит установить версии пакетов с поддержкой GPU без возможного влияния ранее установленных модулей. - Пакеты, которым для установки необходимо наличие GPU, необходимо предварительно скачать, затем выделить вычислительный узел с GPU и установить пакет с локального каталога. Например, для установки пакета pytorch_scatter из git-репозитория следует выполнить следующие команды:
git clone https://github.com/rusty1s/pytorch_scatter
srun --pty --cpus-per-task 1 --gpus 1 bash
cd pytorch_scatter
pip install -e .
Здесь точка в конце команды означает указание на текущий каталог - будет выполнена сборка и установка модуля из текущей директории. - Провести проверочный запуск на 1 GPU и подготовить скрипт-файл для sbatch по примеру из инструкции по запуску задач на суперкомпьютере.
Пример sbatch-скрипта:
#!/bin/bash #SBATCH --job-name=test #SBATCH --gpus=1 module purge module load python source deactivate source activate my_py_env nvidia-smi which python python -V python -c 'import torch; print(torch.cuda.is_available())'
Важно: о выводе результатов в консоль
По умолчанию python использует буферизованный вывод (т.е. вывод НЕ мгновенно передается в результирующий файл).
Например, в случае такого кода:
from time import sleep
print('Start')
for i in range(60):
sleep(1)
print('Done')
Начальный вывод "Start" появится в файле вывода (slurm-.out) только спустя 60 итераций (одновременно с "Done").
Для задач, результаты которых оцениваются в процессе выполнения (выводятся промежуточные значения и тп), это не подходит (например, в случае, когда задача завершится по таймауту, вывода в файле не будет).
Для мгновенного отображения результатов предлагается 2 варианта:
- Добавлять аргумент flush=True в функцию print: print('Start', flush=True) (это работает только при версии python >= v3.3).
- Добавить аргумент -u при запуске задачи к самому интерпретатору: например, python3 -u myprog.py (изменений в коде в данном случае не понадобится).
Регистрация на суперкомпьютере 👉 https://hpc.hse.ru/users/registration
Инструкции для пользователей 👉 https://hpc.hse.ru/support/instructions
![]()
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.